GPU在视频转码中的应用研究进展
已有的视频转码软件
目前,市场上已经出现了几款优秀的利用GPU进行辅助视频转码的软件,典型的代表包括nVidia的Badaboom,AMD的ATIAvivo,Cyberlink的MediaShow和免费软件MediaCoder。其中,前三者均为商业软件,只有MediaCoder是免费软件。MediaCoder在2008年仍是基于GPL协议的开源软件,后来作者封闭了源代码,不再开源,但仍可以获得免费版本。
网上已有这几款软件的评测文章,比如网易09年的这篇文章。此文的结论简言之,便是nVidia的Badaboom充分发挥了GPU的性能,将计算任务最大地交给GPU来做;而MediaCoder则将部分计算任务放到GPU中,CPU的负载也很重,更容易使CPU和GPU同时满负载。
基于CPU的视频转码方案—以ffmpeg为例
-
识别文件格式,打开视频文件容器,得到video_stream
-
使用解码器(如libavcodec)把video_stream解码成原始的frame数据
-
利用编码器将frame数据编码成指定格式(如H.264)
-
存放到指定格式的容器中(如mp4或者mkv)
过程1的速度很快,没有必要使用GPU更改,可以使用已有的代码。
过程2和过程3需要对每一帧进行编解码处理,计算量大,计算任务可并行的程度高,因此可以使用GPU进行优化。
过程4与过程1类似。
基于GPU的并行计算技术的选择,CUDAvs OpenCL
目前,GPGPU的编程框架主要有两种,一种是nVidia公司推出的CUDA(ComputeUnified
DeviceArchitecture,统一计算架构),目前只能在nVidia公司的显卡中使用;另一种是由非盈利性技术组织KhronosGroup掌管的OpenCL。OpenCL最初由苹果公司提交,后来获得了包括nVidia和AMD在内的工业界领袖的支持,正式成为国际标准。OpenCL不仅可以在nVidia公司的显卡中使用,还可以在AMD(ATI)的显卡中使用,是一种可以在异构GPU平台中使用的技术选择。
CUDA
CUDA目前最新的版本是4.0,已经发展了多年,技术上比较成熟。CUDA是一个技术框架,同时提供OpenCL和CUDAC语言的编译器。虽然也有人编写了针对Java或者Python等语言的包装器(Wrapper),但目前使用最多的并且最稳定的是使用CUDAC语言来进行GPU编程。
CUDAC语言是通过对C语言进行扩展实现的。在CUDA的架构下,一个程序分为两个部份:host端和device端。Host端是指在CPU上执行的部份,而device端则是在显示芯片上执行的部份。CUDAC与ANSIC最大的不同之处就是在device端中运行的C程序里加入了一些关键字,从而使得这些程序可以由CUDAC编译器,生成PTX码。
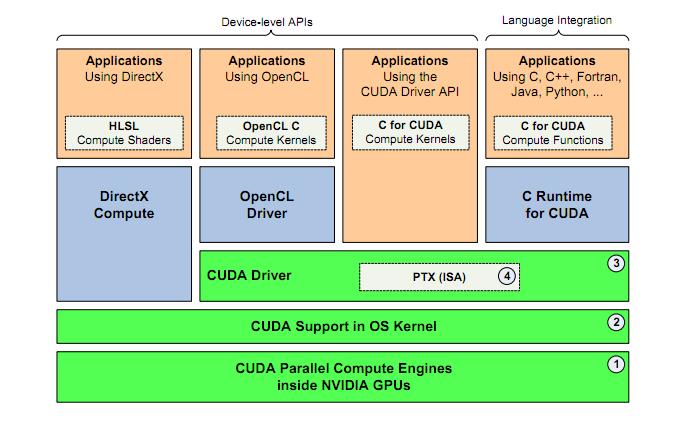
OpenCL
OpenCL目前最新的版本是1.1,由于OpenCL是一个国际标准,因此其更新升级不如CUDA快。为了能在异构的硬件环境中使用,OpenCL的封装层次较低,高层次的抽象Brook本质上是基于上一代GPU的,缺乏良好的编程模型。
对于面向nVidia的GPU编程,短期看CUDA C无疑是最好的选择,不仅因为CUDAC的发展快,技术较为成熟,更重要的是CUDAC编程有丰富的资料和论坛支持,从而更容易上手和解决问题。但对于一个长期项目,在未来的硬件平台不能确定的情况下,使用OpenCL的效果会更好一些。
CPU和GPU都是具有运算能力的芯片,CPU更像“通才”——指令运算(执行)为重+数值运算,GPU更像“专才”——图形类数值计算为核心。在不同类型的运算方面的速度也就决定了它们的能力——“擅长和不擅长”。芯片的速度主要取决于三个方面:微架构,主频和IPC(每个时钟周期执行的指令数)。
-
微架构
CPU微架构的设计是面向指令执行高效率而设计的,因而CPU是计算机中设计最复杂的芯片。和GPU相比,CPU核心的重复设计部分不多,这种复杂性不能仅以晶体管的多寡来衡量,这种复杂性来自于实现:如程序分支预测,推测执行,多重嵌套分支执行,并行执行时候的指令相关性和数据相关性,多核协同处理时候的数据一致性等等复杂逻辑。
GPU其实是由硬件实现的一组图形函数的集合,这些函数主要用于绘制各种图形所需要的运算。这些和像素,光影处理,3D坐标变换等相关的运算由GPU硬件加速来实现。图形运算的特点是大量同类型数据的密集运算——如图形数据的矩阵运算,GPU的微架构就是面向适合于矩阵类型的数值计算而设计的,大量重复设计的计算单元,这类计算可以分成众多独立的数值计算——大量数值运算的线程,而且数据之间没有像程序执行的那种逻辑关联性。
因此从微架构上看,CPU擅长的是像操作系统、系统软件和通用应用程序这类拥有复杂指令调度、循环、分支、逻辑判断以及执行等的程序任务。它的并行优势是程序执行层面的,程序逻辑的复杂度也限定了程序执行的指令并行性,上百个并行程序执行的线程基本看不到。GPU擅长的是图形类的或者是非图形类的高度并行数值计算,GPU可以容纳上千个没有逻辑关系的数值计算线程,它的优势是无逻辑关系数据的并行计算。
-
主频
GPU执行每个数值计算的速度并没有比CPU快,从目前主流CPU和GPU的主频就可以看出了,CPU的主频都超过了2GHz,甚至3GHz,而GPU的主频最高还不到2GHz,主流的也就1GHz。所以GPU在执行少量线程的数值计算时速度并不能超过CPU。
目前GPU数值计算的优势主要是浮点运算,它执行浮点运算快是靠大量并行,但是这种数值运算的并行性在面对程序的逻辑执行时毫无用处。
-
IPC(每个时钟周期执行的指令数)
这个方面,CPU和GPU无法比较,因为GPU大多数指令都是面向数值计算的,少量的控制指令也无法被操作系统和软件直接使用。如果比较数据指令的IPC,GPU显然要高过CPU,因为并行的原因。但是,如果比较控制指令的IPC,自然是CPU的要高的多。原因很简单,CPU着重的是指令执行的并行性。
另外,目前有些GPU也能够支持比较复杂的控制指令,比如条件转移、分支、循环和子程序调用等,但是GPU程序控制这方面的增加,和支持操作系统所需要的能力CPU相比还是天壤之别,而且指令执行的效率也无法和CPU相提并论。
总结一下:
CPU更适合处理逻辑控制密集的计算任务,而GPU适合处理数据密集的计算任务。并且由于现代CPU的发展,使得CPU与计算机主存的交换速度要远远大于GPU与计算机主存的交换速度,因此GPU更适合处理SIMD(SingleInstruction
MultiData,单数据多指令)的运算,即将数据放到显存中进行多次计算的计算任务。
目前比较流行CPU+GPU的协同计算模型,在这个模型中,CPU与CPU协同工作,各司其职。CPU负责进行逻辑性强的事物处理和串行计算,GPU则专注于执行高度线程化的并行处理任务。CPU、GPU各自拥有相互独立的存储器地址空间:主机端的内存和设备端的显存。
三网融合下自适应编码技术的研究
在三网融合业务发展中,信息服务将覆盖文字、语音
数据、图像、视频等多种媒体信息综合服务形式,同时用户使用的终端也将呈现多样化。为了达到用户体验的一致,又能适合各种不同终端处理、不同网络传输的目标,需要多种自适应、自适配的机制和技术,而自适应编码技术就是解决关键的视频数据信息处理和传输的方法和环节之一。
自适应编码技术
H.264/SVC(可扩展视频编码)在进行视频信号编码时,将图像压缩信号的输出分成多个不同的层。当网络条件较差、带宽不足时,网络和终端只对基本层的码流数据进行传输和编码;而当带宽条件改善,则可以进一步传输和解码增强层的码流,提高视频图像质量。
SVC于2007年7月成为H.264标准的一部分。当前大部分的研究和试验都是基于H.264进行的,但实际上SVC技术也可以应用于启天的视频编码格式,并不限于H.264编码。
三网融合中自适应编码的应用
视频业务质量提升
SVC可以在网络质量不佳时自动地通过降低码率来保证播放的流畅性,在网络质量好时通过增强码来提升视频质量,可以同时适用IPTV、互联网和3G网络,提升用户体验。
三屏互动业务的开展
目前,手机、电视和电脑是三个主要的视频终端,使用SVG技术,可以使同一个文件在这三个不同的终端中进行播放。
同时,三屏互动业务中终端形态各异、能力各不相同,当进行互动和互通时,信息适配是核心问题,而SVG技术可以通过将视频分为基本层和增强层来很好地解决这个问题。
内容统一编码和存储
在三网融合模式下,必须对内容源头进行统一的引入、统一编码和存储,只有这样才能实现三屏互动、三屏同看等相关的新型业务类型。原有那种内容各自引入、各自编码和存储的模式已经无法适应新形式的需要了。同时,随着内容数量的急剧增大,内容管理和运营的工作量急剧上升,要满足内容运营的及时性和丰富性,必须使用统一、有效的内容管理模式和存储模式。而SVC编码方式可以使用同一个媒体文件存储不同层次的编码流数据,而且这些流数据本身具有极大的图像相关性,在节省存储空间的同时,又为不同屏幕、不同分辨率、不同接入环境提供相应的视频服务。因此,应该尽量在统一内容管理和统一内容存储技术中引入SVC,完成内容编码和存储的统一处理和统一管理。在这种模式下,要求使用SVC技术对同一内容源进行编码,然后存储成多个分层,分别对应手机、PC、电视机等不同终端和网络条件,可以实现一个内容存储文件适配所有终端和网络条件。
自适应编码关键技术
自适应转码技术
主要有全编全解转码和部分编解码两种方式。全编全解转码是通过将视频进行完全解码和完全编码,效果好,效率低;部分编解码是通过丢弃掉一些不重要的部分来实现,效果差一些,转码效率高一些。
目前,自适应转码技术的研究重点在MPEG-2转H.264上,最新的研究包括H.264变换域转码、H.264快速模式选择算法、H.264转码快速运动估计技术等。
码流自动切换
其原理是将一个视频进行数据分层,使用SVG技术针对不同的带宽情况发送不同层次的数据。目前这种技术的瓶颈在标准的制定上。
SVC文件封装标准
当前,H.264视频封装的媒体文件标准为MP4,事实上还存在着FLV、MKV、TS流文件等多种形式。在MP4文件格式标准中,不同码率或分辨率的媒体数据可以以不同的轨道进行保存,两个轨道之间互不影响。因此对于SVC码流文件的封装可以采用基本层和扩展层分轨道保存的形式,并同时在媒体文件索引头结构中增加相应的标识位,标识相应的分层编码信息。
目前,SVC的文件封装格式尚未出现真正的标准,是推广SVC技术的最大障碍。
SVC媒体流封装标准与传输机制
在传统媒体应用中,直播流大多采用RTP标准进行封装和传输。为了支持SVC,目前已经有提交给IETF的H.264/SVC封装草案。
在进行SVC的直播流传输中,目前多数研究都是将基本层和增强层数据分成两个不同的信道进行传输,并利用RTP的封装进行增强层的数据差错隐藏,基本层走低误码率通道,增强层走高误码率通道。
三网融合中的IPTV和数字电视都采用了TS流封装格式,网络条件和传输通道都有较好保障。在这种情况下,SVC需要考虑TS
流的封装格式,采用TS
流封装时,通过对 NAL单元进行扩充,区别 SVC基本层和扩展层数
据,TS
层不进行区分,传输可继续采用原有的单通道传输模式。
带宽检测技术
在多码率自适应技术中,带宽检测技术存在一定的缺陷。在网络条件恶劣时,系统可自动从高码率切换到低码率,但从低码率自动切换到高码率的技术目前还不成熟。互联网中使用的和式增加,积式减少的(AIMD)拥塞控制机制已不太合适,面向3G移动网络的带宽检测技术还不成熟。
三网融合自适应编码引入方案
SVC自适应技术需要解码器和编码器的配合,但传统的视频业务终端多样,因此在设计新的系统时要考虑对遗留系统的兼容性。
在构建新的系统时,使用SVC技术对支持SVC的设备输出SVC流,对于遗留设备则输出原始视频流。
使用GPU进行视频编解码
GPU视频编解码研究现状
迄今为止,已有许多关于使用GPU加速视频编解码的文章发表,如下表所示。目前GPU加速视频编码的主要集中在运动估计(ME,Motion Estimate),运动补偿(MC,Motion
Compensation)和帧内预测(Intraprediction)

视频编码—H.264
H.264是目前最好的视频编码标准之一,是一种基于块(Block)的视频编码,H.264支持16*16,8*8,4*4的帧内预测块。它充分利用帧内块(Block)的空间相关性和帧间块(Block)的时空相关性来对视频进行压缩,因此可以达到比较高的压缩率。
H.264是在MPEG-4技术的基础之上建立起来的,其编解码流程主要包括5个部分:帧间和帧内预测(Estimation)、变换(Transform)和反变换、量化(Quantization)和反量化、环路滤波(LoopFilter)、熵编码(EntropyCoding)。下图为H.264的视频编码过程。
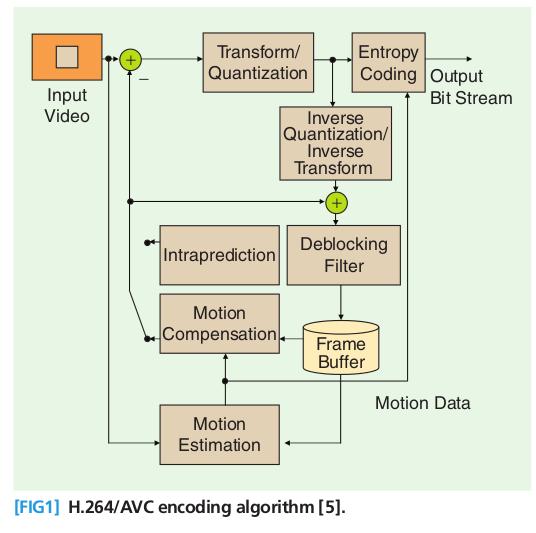
H.264标准的关键技术
1.帧内预测编码
帧内编码用来缩减图像的空间冗余。为了提高H.264帧内编码的效率,在给定帧中充分利用相邻宏块的空间相关性,相邻的宏块通常含有相似的属性。因此,在对一给定宏块编码时,首先可以根据周围的宏块预测(典型的是根据左上角的宏块,因为此宏块已经被编码处理),然后对预测值与实际值的差值进行编码,这样,相对于直接对该帧编码而言,可以大大减小码率。
H.264提供6种模式进行4×4像素宏块预测,包括1种直流预测和5种方向预测,如图2所示。在图中,相邻块的A到I共9个像素均已经被编码,可以被用以预测,如果我们选择模式4,那么,a、b、c、d4个像素被预测为与E相等的值,e、f、g、h4个像素被预测为与F相等的值,对于图像中含有很少空间信息的平坦区,H.264也支持16×16的帧内编码。
2.帧间预测编码
帧间预测编码利用连续帧中的时间冗余来进行运动估计和补偿。H.264的运动补偿支持以往的视频编码标准中的大部分关键特性,而且灵活地添加了更多的功能,除了支持P帧、B帧外,H.264还支持一种新的流间传送帧——SP帧。码流中包含SP帧后,能在有类似内容但有不同码率的码流之间快速切换,同时支持随机接入和快速回放模式。H.264的运动估计有以下4个特性。
(1)不同大小和形状的宏块分割
对每一个16×16像素宏块的运动补偿可以采用不同的大小和形状,H.264支持7种模式。小块模式的运动补偿为运动详细信息的处理提高了性能,减少了方块效应,提高了图像的质量。
(2)高精度的亚像素运动补偿
在H.263中采用的是半像素精度的运动估计,而在H.264中可以采用1/4或者1/8像素精度的运动估值。在要求相同精度的情况下,H.264使用1/4或者1/8像素精度的运动估计后的残差要比H.263采用半像素精度运动估计后的残差来得小。这样在相同精度下,H.264在帧间编码中所需的码率更小。
(3)多帧预测
H.264提供可选的多帧预测功能,在帧间编码时,可选5个不同的参考帧,提供了更好的纠错性能,这样更可以改善视频图像质量。这一特性主要应用于以下场合:周期性的运动、平移运动、在两个不同的场景之间来回变换摄像机的镜头。
(4)去块滤波器
H.264定义了自适应去除块效应的滤波器,这可以处理预测环路中的水平和垂直块边缘,大大减少了方块效应。
3.整数变换
在变换方面,H.264使用了基于4×4像素块的类似于DCT的变换,但使用的是以整数为基础的空间变换,不存在反变换,因为取舍而存在误差的问题,变换矩阵如图5所示。与浮点运算相比,整数DCT变换会引起一些额外的误差,但因为DCT变换后的量化也存在量化误差,与之相比,整数DCT变换引起的量化误差影响并不大。此外,整数DCT变换还具有减少运算量和复杂度,有利于向定点DSP移植的优点。
4.量化
H.264中可选32种不同的量化步长,这与H.263中有31个量化步长很相似,但是在H.264中,步长是以12.5%的复合率递进的,而不是一个固定常数。
在H.264中,变换系数的读出方式也有两种:之字形(Zigzag)扫描和双扫描,如图6所示。大多数情况下使用简单的之字形扫描;双扫描仅用于使用较小量化级的块内,有助于提高编码效率。图6变换系数的读出方式
5.熵编码
视频编码处理的最后一步就是熵编码,在H.264中采用了两种不同的熵编码方法:通用可变长编码(UVLC)和基于文本的自适应二进制算术编码(CABAC)。
在H.263等标准中,根据要编码的数据类型如变换系数、运动矢量等,采用不同的VLC码表。H.264中的UVLC码表提供了一个简单的方法,不管符号表述什么类型的数据,都使用统一变字长编码表。其优点是简单;缺点是单一的码表是从概率统计分布模型得出的,没有考虑编码符号间的相关性,在中高码率时效果不是很好。
因此,H.264中还提供了可选的CABAC方法。算术编码使编码和解码两边都能使用所有句法元素(变换系数、运动矢量)的概率模型。为了提高算术编码的效率,通过内容建模的过程,使基本概率模型能适应随视频帧而改变的统计特性。内容建模提供了编码符号的条件概率估计,利用合适的内容模型,存在于符号间的相关性可以通过选择目前要编码符号邻近的已编码符号的相应概率模型来去除,不同的句法元素通常保持不同的模型。
GPU辅助视频编解码中的挑战
发挥GPU性能的关键在于尽可能地实现数据并行化,因此在视频编解码过程中要注意那些相互依赖的过程,因为控制指令(if,switch,
do, while,etc)在GPU中的执行效率很低,因此应该尽量将这些指令放到CPU中执行。此外,由于GPU访问计算机主存的速度很低,因此应该尽量减少GPU对计算机主存的访问。
视频编解码中计算最密集的任务有三个,分别是运动估计(ME)、运动补偿(MC)和帧间预测编码(Intraprediction),这三个计算任务分别是帧间编码、解码和帧内编码计算任务最密集的部分。此外,也有人对使用GPU进行离散余弦变换(DCT)进行了讨论。
使用GPU进行运动估计(ME)
ME是视频编解码中计算最密集的部分,前期关于使用GPU加速ME的研究集中在使用GPU来计算SAD(Sumof
AbsoluteDifferences)上,SAD用于寻找一个块(Block)的最佳对应块,SAD是通过一个块中的像素与另一个无关块中的像素进行计算活得的。
最新的视频编解码算法使用率失真优化(rate-distortion,RDoptimized)ME,这种算法在选择最佳候选时既考虑rate,又考虑distortion,比如说加权的SAD和运动矢量(MV)的编码率。在RD-optimizedMe的计算中,因为首先要计算相邻blocks的运动矢量(MV),增加了控制逻辑,丧失了一定的独立性,使得使用GPU加速会遇到困难。
基于GPU的ME:循环展开(LoopUnrolling)

通过展开基于SAD的ME中的循环,将其交给并行地计算,可以实现ME的加速。前人的研究证实使用这种方法可以提升ME计算2-13倍的速度。下图为传统的计算ME循环,GPU可以将这些Loop函数转换为并行的计算。

尽管这种方式可以达到很高的并行化,但因为ME和MV分别计算,因此使用运动矢量估计(motionvectorperdition)来优化ME就很困难。而且进行全局搜索(full-search)会使计算量大大提高,因此难以显著地提高ME的计算速度。
基于GPU的ME:重排编码顺序
因为RD-optimizedME算法中存在对相邻块的依赖,因此不能仅仅使用循环展开的方式来达到并行化,因此人们尝试通过调整编码顺序来实现计算的并行化。与传统的栅格扫描的自然序不同,新算法采用了沿对角线进行块计算的顺序,如下图所示。这样,在计算每一个块时相邻块的MV便已经计算出来,而对角线上的块的计算可以达到很高的并行化。在前人的研究中使用这种方法可以提升40倍的速度。
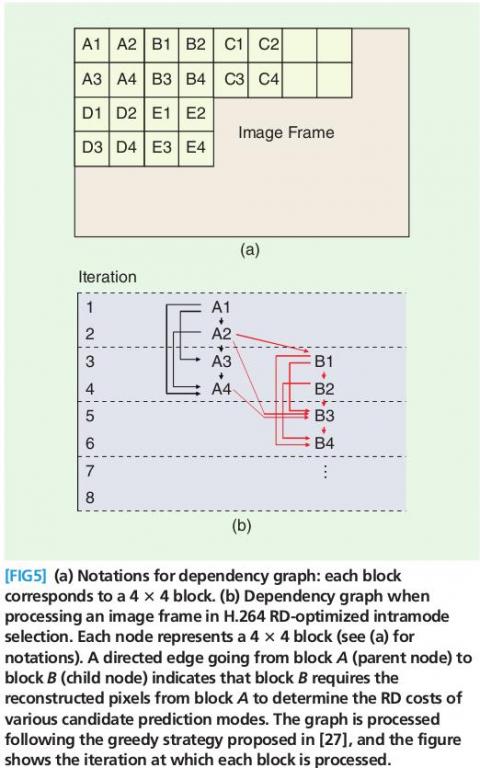
使用GPU计算RD-OptimizedINTRAMODE DECISION
新的视频编码算法是通过计算RD-Optimizedintramodeselections来找到最佳的intra预测编码(intrapredition)方向。在这种算法里,编码器将计算所有候选方向的拉格朗日cost,拉格朗日cost可以看作所有原始块与预测块的平方差和的和(SSD,sum
of sum of square differences)。
将RD-Optimizedintradecision并行化计算是困难的,因为需要使用重建的邻块来计算采样。目前解决这个问题的算法是基于贪心算法,这种算法的原理可以参考右图,实验说明这种方法可以提升2倍的速度。
使用GPU计算运动补偿(MC)
因为视频编码标准允许运动矢量(MV)达到亚像元(sub-pixel)的级别,因此需要大量的插值运算,比如在H.264标准中,产生一个半像元的样点需要对6个像元进行插值。
由于每个像元块可以使用自己的运动矢量信息来独立地计算MC,因此MC的计算可以并行地处理。在前人的研究中,使用这种方法可以提升超过3倍的速度。
CPU和GPU的任务分配
CPU和GPU各有所长,视频编解码中涉及到多种类型的操作,因此需要将CPU和GPU结合使用,才能达到最佳的效果。在这个过程中有几个原则可以参考,比如:
-
尽可能地将任务并行化,时期同时在CPU和GPU上并行地处理。
-
因为GPU与计算机主存的交换速度很慢,因此要尽量减少GPU与主存的数据交换,将数据尽可能地留在GPU中进行计算而不是反复读写。
-
尽可能地将计算任务交给GPU来做,减轻CPU的计算量。
前人对WMV的解码过程进行了分解,将整个反馈环(feedbackloop),包括MC和色彩空间变换(CSC,color spaceconversion)分配给GPU。这样可以减少GPU与CPU之间的数据交换,使数据在GPU中得到充分地计算。下图是这种任务分割的示意图:
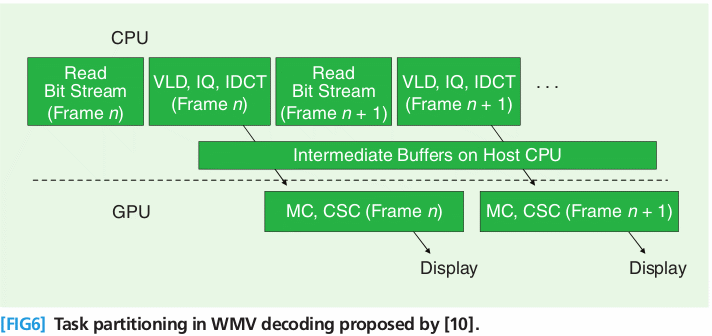
从图中可以发现当GPU在做第n帧的MC和CSC计算时,CPU在做第n+1帧的变长解码(variable-lengthdecoding,
VLD),反量化(inversequantization, IQ)和反离散余弦变换(inversediscrete cosine transformation, IDCT)计算。在CPU和GPU之间使用缓存来解决两者的同步问题,实验证明使用大小为4帧的缓存可以提升整体的速度。
GPU辅助视频转码的困难
尽管已经有采用GPU加速的商业转码软件,但还没有相应的开源软件。相比视频编解码,使用GPU加速进行视频转码的难度要更大,因为视频编解码已经形成了很多标准算法,但转码方面的算法实现并不多,且没有公认的标准算法。
分享到:





相关推荐
基于GPU的视频转码技术研究.pdf
GPU在密码处理领域应用研究.pdf
通过GPU加速数据挖掘的研究进展和实践,GPU在数据挖掘有极大意义
基于GPU的蒙特卡洛模拟在辐射剂量计算中的研究进展及应用.pdf
系统概述了GPU并行优化技术在水利计算中的应用进展;简要介绍了当前应用较多的几种并行技术;建设性提出了该项技术在水库调度、中长期水文预报和水文模型计算中的应用前景和优势;详细总结了应用该项技术的一般方法...
GPU虚拟化技术及应用研究.pdf
通过GPU加速数据挖掘的研究进展和实践.pdf
(1)拷去显存 (3)拷回主存 (2)计算 (1)视频输入 (5)输出 (4)编码 (2)解码 (3)处理
(1)拷去显存 (3)拷回主存 (2)计算 (1)视频输入 (5)输出 (4)编码 (2)解码 (3)处理
基于GPU的粒子系统的研究与应用 基于GPU的粒子系统的研究与应用
粒子滤波GPU实现方面的论文,包含FPGA实现等
将计算密度高的部分迁移到GPU上是加速经典...最后分别基于CPU和GPU实现协同过滤推荐的两类经典算法,并基于经典的MovieLens数据集的实验验证GPU对加速数据挖掘应用的显著效果,进一步了解GPU加速的工作原理和实际意义。
超融合GPU云技术在测绘生产体系中的应用研究.pdf
近年来,图形处理器(Graphics Processing Unit,GPU)的发展相当迅速,GPU 的运算能力及存储带宽均已远远超过目前主流CPU 。将GPU作为CPU 的协处理器 完成大规模数据密集型的计算任务,相对于集群和超级计算机的...
GPU在Android显示系统中的应用与研究.pdf
基于GPU的视频流拼接算法研究.pdf
GPU在活塞销尺寸快速检测中的应用研究.pdf
GPU的通用计算应用研究.pdf
云计算-通用GPU计算在分类算法中的研究与应用.pdf
流式缩减技术在GPU上的研究与应用.pdf